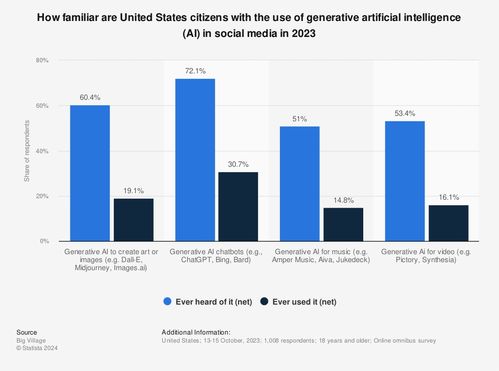
木材染色廢水處理技術配方合作與設備轉讓

隨著木材染色行業的快速發展,廢水處理問題日益突出。我們提供專業的木材染色廢水處理技術配方合作機會,同時轉讓相關二手設備,助力企業實現環保合規與成本優化。
木材染色廢水含有高濃度有機染料、重金屬離子和化學助劑,若直接排放將對環境造成嚴重污染。我們的技術配方采用先進的物理化學與生物處理相結合的方法,包括絮凝沉淀、活性炭吸附以及高效微生物降解工藝,能有效去除廢水中的有害物質,使出水達到國家排放標準。
除了技術配方,我們還提供配套的二手廢水處理設備轉讓服務,包括沉淀槽、過濾器、生化反應器等。這些設備經過嚴格維護,性能穩定,可大幅降低企業初始投資成本。我們誠邀木材加工企業、環保工程公司及相關行業伙伴進行技術合作與設備采購,共同推動綠色生產。
如有合作意向,請通過世界工廠網中國產品信息庫聯系我們,獲取詳細技術參數與報價。
如若轉載,請注明出處:http://m.jy2008.cn/product/3.html
更新時間:2026-06-07 21:03:55